
Patrick Vennebush over at Math Jokes 4 Mathy Folks just posted an interesting problem:
Three points are randomly chosen along perimeter of a square. What is the probability that the center of the square will be contained within the triangle formed by these three points?
I would like to present my own thinking on the problem, but before I even get started, two important points. First, I wrote all of the following discussion as I solved the problem—the goal was as much to display the thought process and see if there was an “Aha!” moment (as Vennebush describes). Second, I am not even certain that the final result is correct, or that the logic is sound. I think it is, but I eagerly await Vennebush’s solution, that I might compare it to my own.
The first thing that I did was try to get a handle on what kinds of configurations of points will create triangles containing the center of the square. I drew several squares, and put points on the perimeter, and tried to note when the triangle formed by those points contained the center.
After a few minutes, I concluded that there were basically four cases:
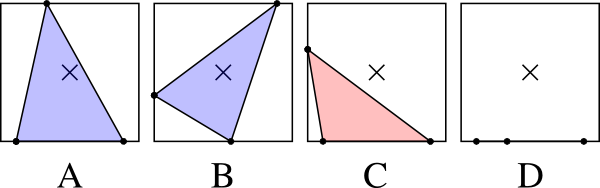
In case A, two points are on one side of the square, while the third point is on the opposite side. If this happens, there is a chance that the triangle formed will contain the center of the square, though it is not certain. In case B, all three points are on different sides of the square. Again, the triangle could contain the center, but it is not certain. In case C, two points are on one side of the square, and the third is on an adjacent side. In this case, we can know for certain that the triangle will not contain the center of the square. Finally, in case D, all of the points end up on the same side of the square, and no triangle is formed.
Once I had done this, the problem devolved into two smaller problems: first, determine the probability of each case; and second, determine the probability of the resulting triangle containing the center of the square.
My thinking was as follows: I started by placing a point X on the square at random. Ultimately, I only care about where the other points fall relative to X, so it doesn’t really matter which side of the square X lands on. To make life easy for myself, I put X at the bottom, with the understanding that if X fell somewhere else, I could just rotate the square to get it to the bottom.
Once X is placed on the bottom, the two remaining points could fall on the bottom (b) side, the top (t) side, the left (l) side, or the right (r) side, each with equal probability. Hence there are 10 possible different configurations, each of which is equally likely: bb, bt, bl, br, tt, tl, tr, ll, lr, and rr.
If both of the new points fall on the bottom, then we have case D from above, and the configurations bl, br, ll, and rr lead to case C. Thus with probability 5/10 = 1/2, we can conclude that no triangle can be formed without doing any further work. In either case, no triangle containing the center of the square can be formed. Case A occurs with the configurations bt and tt, so case A occurs with probability 2/10 = 1/5. Finally, the remaining configurations lead to case B, with probability 3/10.
The next step was to figure out the probability of cases A and B creating triangles that contained the center of the square. I started with case A.
To do this, I drew a square, and put two points on the bottom side. I then tried to figure out where the third point would have to be in order to contain the center of the square. The first thought that sprang to my mind was that if we drew a segment from either point to the opposite of the square, passing through the center of the square, that segment would contain the center. Hence a point directly opposite from either of the original two points would lead to a triangle containing the center of the square. Moreover, the two points opposite the original two points defined the boundaries of a region in which I could place a third point, and be guaranteed to contain the center (shown in purple, below).
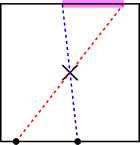
When I first saw this purple segment, a lightbulb when off in my head. I had a little “Aha!” moment. The four cases I had discovered earlier were utterly irrelevant. Once I plopped down two points, I could draw segments through the center of the square, and define a region where the third point needed to fall. It didn’t matter where the first two points were, or how they were configured.
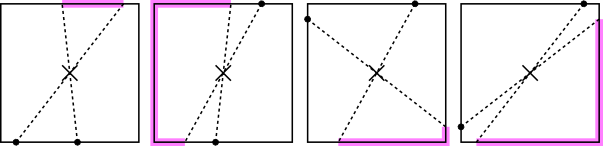
It turns out that if I already have points X and Y, the probability of point Z landing in the purple zone is the “city-block” distance1There are a lot of ways of the measuring distance between two points. The two that are most familiar to us are “as the crow flies,” which connects two points with a straight line and measures the length of that line; and “city-block” distance, which requires that we travel along a square grid, like the roads in a city. In this case, we are measuring the distance from X to Y along the perimeter of a square, so we use city-block distance. between X and Y divided by the perimeter of the square.2There is one exception: if X and Y are can be joined by a segment that passes through the center of the square, i.e. they are opposite each other, then wherever Z is placed, the resulting triangle will contain the center of the square. However, this happens with probability 0, so we can safely ignore this possibility. To make things easy, I assumed that the perimeter of the square was 1 unit, so the probability of Z falling where I wanted it was just the distance between X and Y.
That’s all well and good, but how far apart are X and Y, and with what probability? I needed to step back a bit, so I asked what would happen if X were fixed. Then the city-block distance between X and Y would be determined by the random position of Y. Y could happen to fall right on X, giving a distance of 0; it could fall exactly opposite X, giving a distance of 0.5 (I was still assuming a perimeter of 1); or it could fall on any other point between with uniform likelihood.3By “uniform likelihood,” I mean that every possible point is equally likely, meaning that any distance between 0 and 0.5 (exclusive) is equally likely.
This presented a bit of a problem for me, because it has been a while since my last probability class, and I wasn’t quite sure how to handle the continuous distribution of distances. However, I had another thought: “What if I discretized the problem? Instead of dealing with continuous distribution of possible locations for Y, why don’t I try to figure out what happens when I assume that Y can only fall on a finite number of points?” The model looks something like this:
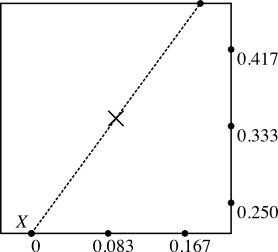
In this image, I have assumed that Y falls on one of 5 points which are equally spaced between X and the point opposite X on the square. Each of the points is labeled with its distance from X. Also note that each of the labeled points has a corresponding point on the other side of X, but that this doesn’t actually change the calculations at all.
To find the probability of creating a triangle that contains the center of the square, all I need to do is average the probability of creating such a triangle across each of the possible locations of Y. The calculations look like this:
(0.083+0.0167+0.250+0.333+0.417)/5 = 0.25
A more general formula is given by
\(\sum_{i=1}^{n}\left({0.5\over n+1}\right)i\over n\).
Basically, this says that if I have n points, then the distance between any two consecutive points is going to be 0.5/(n+1) units. Hence the distance from X to the ith point will be (0.5/(n+1))i units. As there are n points, I added up the probabilities for each point, then divided by n to find the average. If that isn’t very clear, I’m sorry—I can’t claim that it is entirely clear in my head.
At any rate, I am ultimately concerned with points falling on a continuum, rather than on a discrete set of points. Hence I am going to have to take the limit of the above formula as the number of points goes to infinity. That is, I need to find
\(\lim_{n\to\infty}\left(\sum_{i=1}^{n}\left({0.5\over n+1}\right)i\over n\right)\).
Initially, I thought that this looked a bit like a Riemann sum, where the term 0.5/(n+1) looked a bit like a Δxi term. This implies that the problem could probably be approached from the standpoint of integral calculus. I started warming up my calculus muscles, but then I noticed that there was some simplification that could be done:
\(\lim_{n\to\infty}\left(\sum_{i=1}^{n}\left({0.5\over n+1}\right)i\over n\right) = \lim_{n\to\infty}\left({0.5\over n(n+1)}\sum_{i=0}^{i=n}i\right)\).
From having worked with sums a fair bit in my life, I recognize the sum in the right-hand term: it is the sum of the first n consecutive integers. From memory, I recalled that this is equal to n(n+1)/2. Had I not remembered that identity, I probably would have gone back to Reimann sums. Thank goodness I didn’t have to. Anyway, this means that
\(\lim_{n\to\infty}\left({0.5\over n(n+1)}\sum_{i=0}^{i=n}i\right) = \lim_{n\to\infty}\left({0.5\over n(n+1)}\right)\left({n(n+1)\over 2}\right) = \lim_{n\to\infty}0.25 = 0.25\).
This number—0.25 or 1/4—is the solution that I propose for the problem. That is, if three points are selected at random along the perimeter of a square, then with probability 1/4, that triangle will contain the center of the square.
I haven’t read your whole solution but there’s already a problem near the beginning: bt and lr and all the combinations with two different sides are twice as likely as the combinations like bb and tt where both points are on the same side. There should be 16 equally likely possibilities as each of the two points chooses one of the four sides at random.
I actually kind of glossed over that a bit. The entire list of combinations would be bb, bt, bl, br, tb, tt, tl, tr, lb, lt, ll, lr, rb, rt, rl, and rr (these being the 16 you come up with). I was thinking more in terms of combinations than permutations (i.e. lr and rl are basically equivalent). Had I continued upon that line of thinking, I suspect (I hope?) that I would have found the error, but the final solution involved another train of thought entirely. ;)
As to the distance being uniformly distributed, you are entirely correct. I seem to have a tendency to over-complicate problems. On the bright side, I feel like I have proven to myself that it really is uniformly distributed.
Thank you for the input.
Now I’ve finished reading your solution and so the error in that probability calculation is irrelevant.
The final answer of 1/4 is pretty clear: if the second point is plopped somewhere uniformly, there’s an equal probability for each taxicab-distance from 0 to 1/2 so on average the distance is 1/4. I don’t think you needed to go through so much worrying to find that! And I suspect that you have found the same solution as PV did.
Nice thinking! Your solution was slightly different from mine, and my solution will be posted in a couple of days. That said, your solution method of discretizing is exactly how my friend Harold Reiter said that he solved the problem — and that should make you proud, because Harold is one of the best problem solvers I know!
My solution also yields an answer of 1/4. That’s not to say it’s right, just that you and I agree.
Huzzah! It is always nice to have one’s results confirmed by another. ;)